
Pythonはスクレイピングが得意です。
でも…

『スクレイピングでクリックできるの?』
『どうやって実装するの?どんな準備が必要?』
『エラー発生時の解消方法は?』
『勝手にスクレイピングして問題ないの?』
こんな疑問に答えます。

Pythonのスクレイピング|Seleniumでクリックする方法

PythonにSeleniumというスクレイピング用ライブラリがあります。
Seleniumでスクレイピングすると自動でクリックできるのです。
他にもスクレイピングするライブラリがありますが、クリックできるのは基本はSeleniumのみ。
(クリックできる他のライブラリを知っている人はコメントで教えてください)
Seleniumでスクレイピングするには下記の2つの準備が必要です。
- Python環境にSeleniumのライブラリをインストール
- Chromeドライバーをダウンロード
Seleniumを利用したスクレイピングでクリックすることができます。
準備と実装する方法をお伝えします。
【Python】Seleniumでスクレイピングする準備
SeleniumでスクレイピングするにはSeleniumライブラリのインストールとChromeドライバーのダウンロードが必要です。
Seleniumのライブラリをインストールする方法
pipのコマンドでSeleniumのライブラリをインストールします。
※Windowsの場合はPython環境を事前に構築してください。
pip install selenium(バージョンを指定する場合)
pip install selenium==3.141.0Python環境がAnacondaの場合はpipをcondaに変更するだけです。
conda install seleniumconda install selenium==3.141.0
Chromeドライバーのダウンロード方法
Seleniumが動作するブラウザはGoogleChromeのみです。
Chromeへつなぐドライバーをダウンロードして利用します。
※GoogleChromeブラウザは事前にインストールしてください。
- Chromeドライバーのダウンロードサイトを開く
- Chromeのバージョンにあったものクリック
(通常は一番上の最新版でOK)
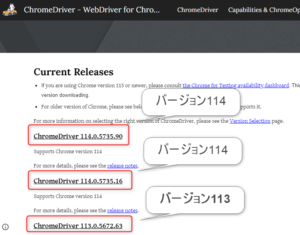
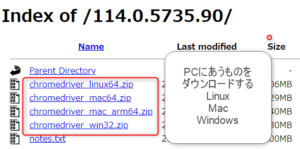
- 実行するOSにあったものをダウンロード
(OS:オペレーティングシステム)
【Python】Seleniumで自動クリックする方法と実装
Seleniumで自動クリックする方法は次の通りです。
- find_element系で要素を取得
find_element_by_partial_link_text
find_element_by_class_name
find_element_by_name
など - 取得した要素でclickメソッドを呼ぶ
また、
「send_keys」で取得した要素にキーボード入力が出来ます。
もちろん従来のスクレイピングと同様にWebサイト表示内容の取得もOK。
続いて、実装です。
次のサンプルコードを参考にしてください。
Seleniumで自動クリックするサンプルコード
SeleniumでChromeドライバーを使用してスクレイビングするサンプルコードです。
~補足~
クリック後にサイトを読み込むケースが多いので3秒待っています:sleep(3)
from Selenium import webdriver
from time import sleep
#chromedriverの場所を指定(chromedriverは事前にWebでダウンロード)
chrome = webdriver.Chrome('例)C:/ちょめちょめ/chromedriver_win32/chromedriver')
sleep(3)
chrome.get("自動でクリックしたいサイトのURL")
sleep(3)
chrome.find_element_by_partial_link_text("リンクTextの文字列").click()
sleep(3)
chrome.find_element_by_name("name名").send_keys("入力したい内容")
chrome.find_element_by_class_name("クラス名").click()
sleep(3)
#終了
chrome.quit()
意外と簡単でしょ♪
SeleniumとChromeのバージョン差異エラーを解消(SessionNotCreatedException)
SeleniumドライバとGoogleChromeのバージョンが合ってないとSeleniumでエラーが発生することがあります。
これがバージョン差異によるエラーです。
【エラーの例】
selenium.common.exceptions.SessionNotCreatedException:
Message: session not created:
This version of ChromeDriver only supports Chrome version 112
Current browser version is 114.0.5735.110 with binary path C:\Program Files (x86)\Google\Chrome\Application\chrome.exe
例のエラー内容をザックリいいますと…
SeleniumのドライバーはChromeバージョン112をサポートします。
現在のChromeバージョンは114です。
というものです。
バージョン差異が発生していますね。
バージョン差異のエラーを解消する方法
Chromeのバージョンを確認し、バージョンに対応したSeleniumドライバーを再ダウンロードします。
Seleniumのドライバーダウンロード先はこちら。
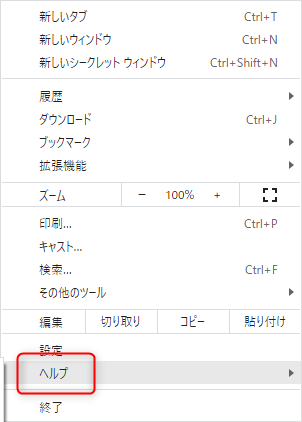
Chromeのバージョン確認方法
- Chromeの右上の3点マークをクリック

- ヘルプをクリック
- GoogleChromeについてをクリックする
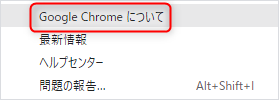
- バージョンを確認できる画面が表示

スクレイピング 禁止サイトの確認方法

意外と簡単なスクレイピングですが、違法となる可能性があります。
違法でないことを確認してからスクレイピングしましょう。
robots.txtでクローラーがアクセス禁止のURLを確認
robots.txtとはクローラーにアクセスを許可するURLと禁止するURLを書いているファイルです。
「WebサイトのURL/robots.txt」で簡単に確認できます。
例)Amazonの場合「https://www.amazon.co.jp/robots.txt」
- user-agent: ルールを適用するクローラを指定します。
- allow: クロールを許可する URL パス。
- disallow: クロールを許可しない URL パス。
- sitemap: サイトマップの完全な URL。
詳細はこちら:Googleによるrobots.txtの指定の解釈
スクレイピングが問題となるケース
下記ケースのスクレイピングは禁止されています。
- robots.txtに記載されたクローラがアクセス禁止のURL
- 利用規約で自動収集(スクレイピング等)が禁止されたサイト
Webサイトにログインするスクレイピングも問題となる可能性が高いです。
(趣味で自作したログインを含むサイトなどは別ですが)
下記のスクレイピングも問題となる可能性があります。
- スクレイピングで頻繁にサーバーアクセスする
- 情報解析以外の目的でスクレイピングする
以上のことに注意してスクレイピングを行いましょう!
「記事を読んでもわからないトコがある」「内容が変だよ」
という時は、お気軽にコメントください♪
「もっとSEおっさんに詳しく聞きたい。何かお願いしたい!」
という時は、ココナラまで。メッセージもお気軽に♪
LINEでのお問合わせも受付中!
LINE公式アカウント
メッセージをお待ちしています!
- 応用情報技術者
- Oracle Master Gold
- Java SE Gold
- Java EE Webコンポーネントディベロッパ
- Python エンジニア認定データ分析
- 簿記2級




