皆さん、こんにちは!

『AI・機械学習・ディープラーニングの違いはなんだろう…』
『ビッグデータを使うのがディープラーニング?』
『AIの歴史も知りたい…』
こんな疑問に答えます。

[toc]
AIと機械学習とディープラーニングの違い
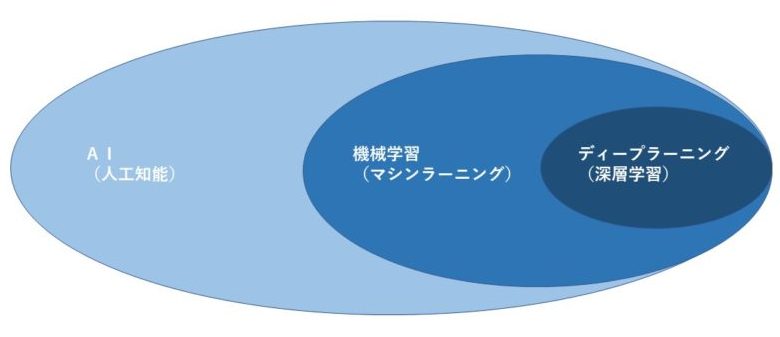
『機械学習とディープラーニング』は『AI』の分野です。
『ディープラーニング』は『機械学習』の分野です。
分野の範囲は
AI>機械学習>ディープラーニング
となります。
つまり…
- 『AI』と言えば『機械学習』も含む
- 『機械学習』と言えば『ディープラーニング』も含む
ということです。
インターネットの普及により、大量の入力データを簡単に入手できるようになりました。
大量の入力データを『ビッグデータ』と言います。
機械学習はビッグデータを元に解析します。
『機械学習』と言えば『ディープラーニング』も含むのですが、機械学習とディープラーニングの違いは何でしょうか?
続いて説明いたします。
機械学習とディープラーニングの違い

機械学習とディープラーニングの違いは…
『機械が特徴量を設定するか、人間が特徴量を設定するか』
の違いです。
特徴量の設定を学習により繰り返し、予測・認識の精度を上げて行きます。
つまり、
ディープラーニングは『機械が自分自身で学習する』ということです。
- 機械が入力データに存在するパターンやルールを発見する
- 人間がデータの特徴量を調整して、予測・認識の精度を上げる
- 機械が入力データに存在するパターンやルールを発見する
- 機械がデータの特徴量を調整して、予測・認識の精度を上げる
精度を上げるための特徴量設定の繰り返し
機械学習もディープラーニングも学習しますので、学習するコト自体に両者の違いはありません。
違いは、人が学習させるか、機械が学習するかです。
歴史でわかるAI・機械学習・ディープラーニングの違い(第1次ブーム~第3次ブーム)

AI→機械学習→ディープラーニングという順番に言葉が生まれてきました。
何故この順番かといいますと…
『時代の流れ』とともに、技術が改善されて新たな名前を生み出して来たためです。
AIの歴史を辿ると、AI・機械学習・ディープラーニング誕生した理由もわかります。
では、AIの歴史を見ていきましょう。
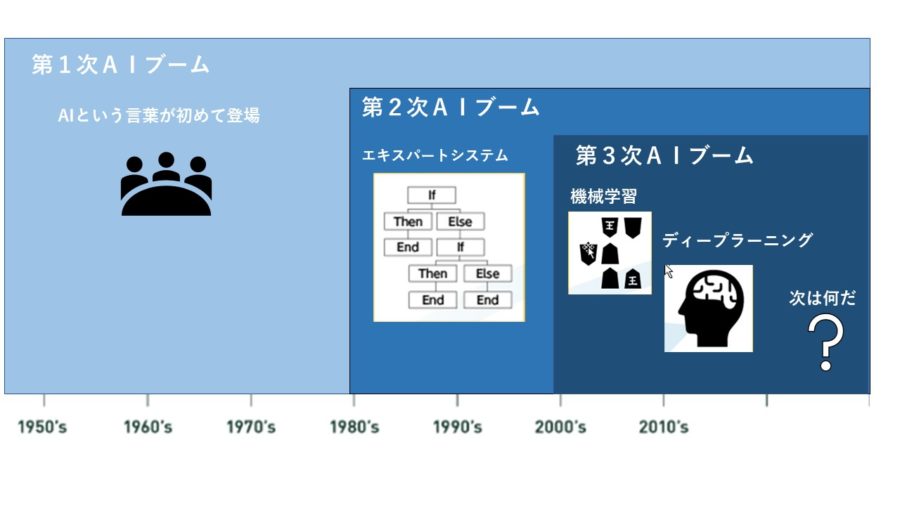
第1次AIブーム:1950年代後半~1960年代
「推論」や「探索」が可能なAI
迷路の解き方のような単純な問題を扱えた。
当然ながら、複雑な現実社会の課題を解くことはできなかった。
言葉(定義)が生まれたぞい!
第2次AIブーム:1950年代後半~1960年代
知識(※1)を使ってルールベースの推論や探索が可能なAI
人工知能(AI)が実用可能な水準に達し、多数のエキスパートシステムが生み出された。
※1)コンピュータが推論するために必要な情報を、コンピューターが認識できる形で人間が記述したもの
※2)専門分野の知識を取り込んで推論し、専門家のように振る舞うシステム
つまり…
人間がインプットされたルール(知識)に 基づいてアウトプットするAIです。
世にある情報全てを、人間がインプットとして用意することは困難なため、
実際活用可能なインプットは特定の領域の情報などに限定する必要がありました。
結局はIf文のということじゃ
もし~ならコレ
もし~ならコレ
でルールを決めるぞい
第3次AIブーム:2000年代~現在
インターネットが普及し「ビッグデータ」を活用することでAI自身が知識を獲得する機械学習が実用化されます。
何よりも『インターネットの普及』が、機械学習の実用化に影響している訳ですね。

第2次AIブームで課題となっていた、インプットデータの問題が解消されます。
続いて、脳のネットワークをモデル化した機械学習であるディープラーニングが登場します。
ディープラーニングは、知識を定義する特徴量をも人工知能(AI)が自ら習得できます。
このディープラーニングの登場で、実社会への実用化が一気に進みました。
機械学習の仕組み

従来の機械学習では、人間が特徴を定義します。
「特徴」というインプットは人間の手で行うということです。
人間が定義するのでパターンにも限界があり、複雑な特徴を表現できません。
超ザックリと言ってってしまいますと…
機械学習で作成したPGはIF文の塊です。
プログラミングした通りに動いているだけ。
- IF(もしも)aの特徴だったら…答えはx
- IF(もしも)bの特徴だったら…答えはy
- IF(もしも)cの特徴だったら…答えはz
みたいな感じです。
機械学習のPythonライブラリ
機械学習で有名なPythonのライブラリは、scikit-learnです。
このライブラリだけで、以下の様々な分類・回帰・クラスタリングアルゴリズムを備えています。
- サポートベクターマシン
- ランダムフォレスト
- K近傍法
- DBSCAN
ディープラーニング以外の
機械学習はコレでOK
ディープラーニングの仕組み

ディープラーニングは、機械自身がデータの特徴量を調整して、予測・認識の精度を上げます。
機械学習に比べて人工知能っぽくなっていますね。
ただ、ここで勘違いして欲しくないことは…
Deep Learning でも インプット(データセット)は人間が行います。
インプットなしにアウトプットはありません。当たり前ですが^^
ポイントは「特徴」のインプットを人間が行わないということです。
ディープラーニングは「特徴」を「学習」により取得します。
- 出力と正解との誤差が少なくなるように特徴を設定する
- 特徴の設定を繰り返し実行し、精度を上げる
特徴を最適化する
これがディープラーニングじゃ
では、どうやって人工知能が学習していくのでしょうか?
学習とは『テストの答え合せで間違い箇所を復習して、次に活かす行為』です。
ディープラーニングに置き換えると…
『入力データが出力結果に影響する特徴量を調整して、予測・認識の精度を上げること』です。
つまり、特徴量設定の繰り返しを行っているわけです。
次の順で特徴量を設定を繰り返しています。
- 入力データより求めた出力データと正解データを比べる誤差を求める(答え合わせ)
- 誤差が最小になるように特徴量を設定する(誤差逆伝播法)
基本の仕組みはこちらの記事で理解できます。

ディープラーニングのPythonライブラリ
ディープラーニングでPythonのライブラリ(フレームワーク)で有名なものは4つです。
- TensorFlow
- keras
- pytouch
- chainer
TensorFlowはGoogleが提供していおり、「Define-and-Run」方式を採用しています。
「Eager Execution」と呼ぶ機能を利用すると「Define-by-Run」でも実行できます。
Keras・pytouch・Chainerは「Define-by-Run」と呼ばれる方式を採用しています。
計算グラフを定義してから計算を実行する
- 計算の実行時に同時進行で計算グラフが定義される
- データの構造が変わった際のモデルの再構築が楽にでき、デバッグも容易
Chainerは日本の企業であるPreferred Networksが提供しています。
AIの未来:第4次ブームはいつ?弱いAIと強いAIとは
ディープラーニングの登場で、今はAIの実用化が進んでいます。
自動運転、自動翻訳など、自動ホニャララという言葉で良く使われます。
ただ、まだまだ弱いAIです。
弱いAIと強いAIとは…
臨機応変(汎用的)に対応できる考える
例)ドラえもん
特化した処理のみ対応できる
例)自動運転
SFやマンガの世界で登場するAIは、ほとんど強いAIです。
さて、
『ディープラーニングでドラえもんを実現できるか?』
と言われると少し疑問です。
何らかのアルゴリズムのブレークスルーが必要かもしれません。
それが現れると、第4ブームの到来かもですね。

ちなみに…
人工知能(AI)が人類の技術や知能を超え、
AIが文明の主役になる時点のことを、
シンギュラリティ(技術的特異点)と呼ばれています。
さて、今後の未来はどうなるでしょうか?
「記事を読んでもわからないトコがある」「内容が変だよ」
という時は、お気軽にコメントください♪
「もっとSEおっさんに詳しく聞きたい。何かお願いしたい!」
という時は、ココナラまで。メッセージもお気軽に♪
LINEでのお問合わせも受付中!
LINE公式アカウント
メッセージをお待ちしています!
- 応用情報技術者
- Oracle Master Gold
- Java SE Gold
- Java EE Webコンポーネントディベロッパ
- Python エンジニア認定データ分析
- 簿記2級