
AIに興味があるアナタ。
今回はGoogleColabで犬猫の画像判定AIを作る方法をご紹介します。
初心者にやさしい深層学習フレームワークはKerasを利用しました。
画像判定の1歩として犬か猫を画像判定させてみましょう。
でも…

『具体的にどうすんの?』
『画像の準備は?』
こんな疑問に答えます。

GoogleColabで犬猫の画像判定AIを作る前準備
GoogleColabで犬猫の画像判定AIを作りたいところですが、事前準備が必要です。
事前準備はとっても簡単だよ。Let’s Try!
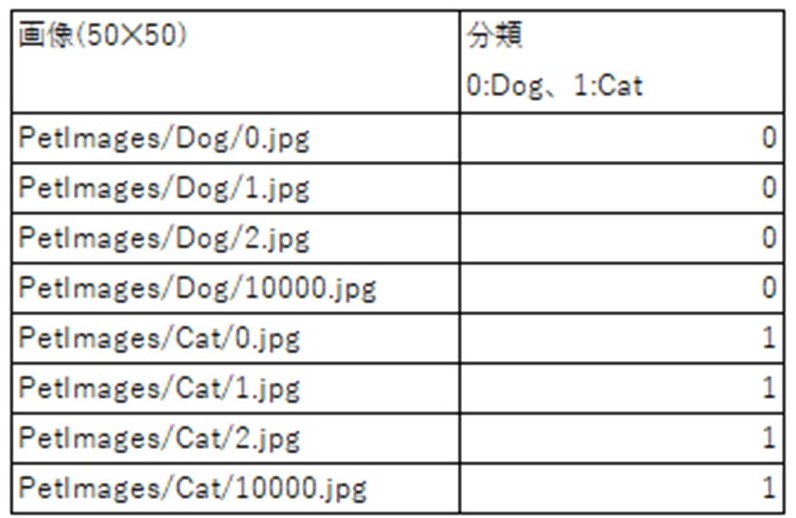
犬猫画像をダウンロード
Micrsoftが提供する犬と猫の画像をダウンロードしてみよう
コチラのサイトより、Kaggle Cats and Dogs Datasetをダウンロードできます。
「Download」ボタンをクリックしてね。
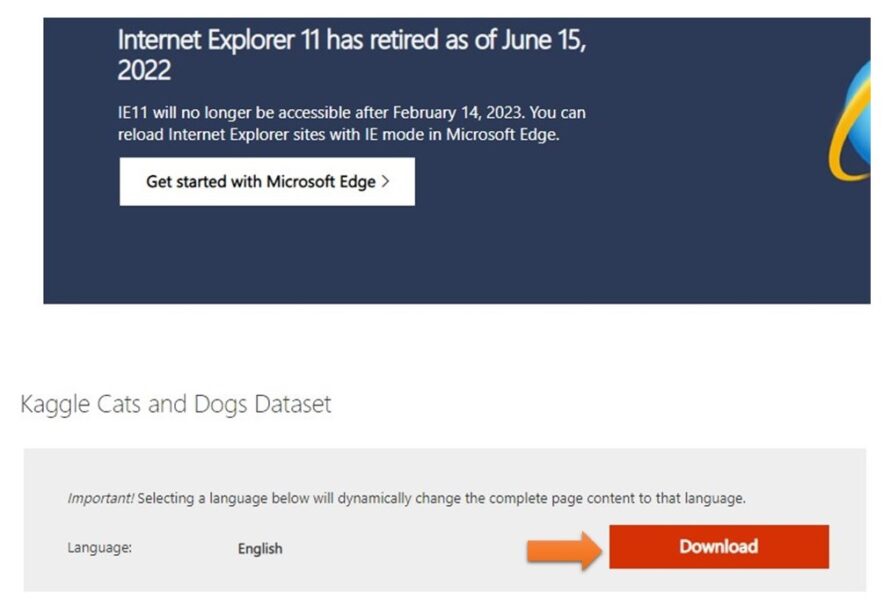
ダウンロードに成功すると「kagglecatsanddogs_5340.zip」
というZIPファイルという圧縮ファイルがPCに保存されます。
780MBあるので結構時間がかかるよー^^;
ちなみに、
ファイル末尾の数字「5340」はダウンロードの時期で変化するかもです。
犬猫の画像のZIPをGoogleドライブへアップロード
ダウンロードしたZIPファイルを、マイドライブの直下にアップロードします。
解凍すると大容量になるので、ZIPのままアップロードしてね。
GoogleColabで解凍コマンドを実行(後述)するのでZIPで大丈夫です♪
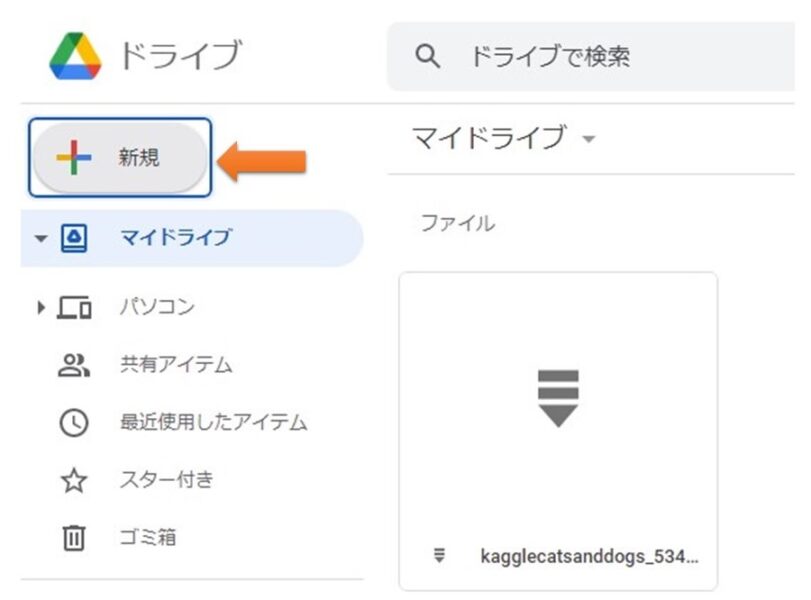
GoogleColabでGoogleドライブをマウント
次はZIPファイルを解凍する準備です。
GoogleColabを開いて、Googleドライブをマウントしよう。
オレンジの矢印の箇所をクリックしてね!
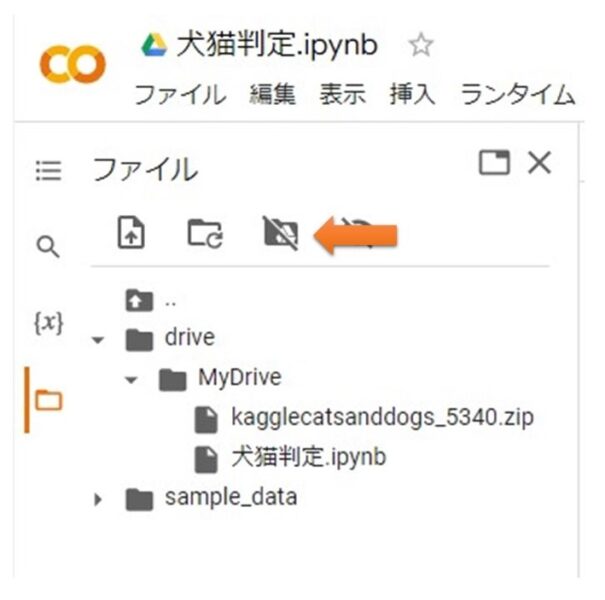
GoogoleドライブへアップロードしたZIPファイルがディレクトリ「drive/MyDrive」に表示されたら成功です!
ColabからGoogoleドライブへマウントできてます。

GoogleColabでZIPファイルを解凍
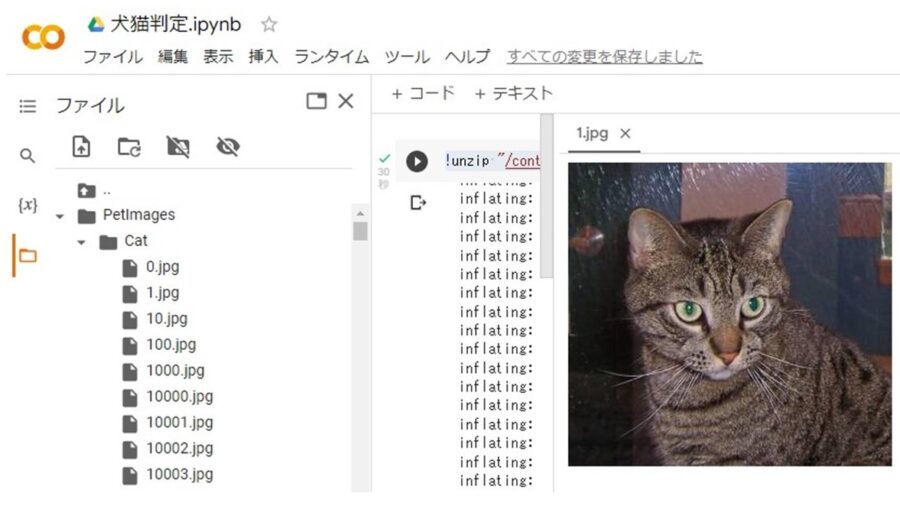
次のコマンドでZIPファイルを解凍します。
!unzip "/content/drive/MyDrive/kagglecatsanddogs_5340.zip"解凍すると、こんな感じのディレクトリ構成になります。
PetImages/Dog/0~12499.jpg
PetImages/Cat/0~12499.jpg
DogとCatのディレクトリ配下に画像が展開されてますね♪
ちなみに、ファイル数を確認するコマンドはこちら
!ls -1 PetImages/Dog |wc -w12501

GoogleColabのランタイムをGPUへ変更
ソースを書く前にGoogleColabのランタイムをGPUへ変更します。
これをすると実行が早くなるよ。

GoogleColabでCNN犬猫画像判定AIを作る♪
いよいよ犬猫画像の判定です。
今回はCNN(Convolutional neural network:畳込みニューラルネットワーク)で、犬猫画像を判定させます。
イメージはこんな感じ。
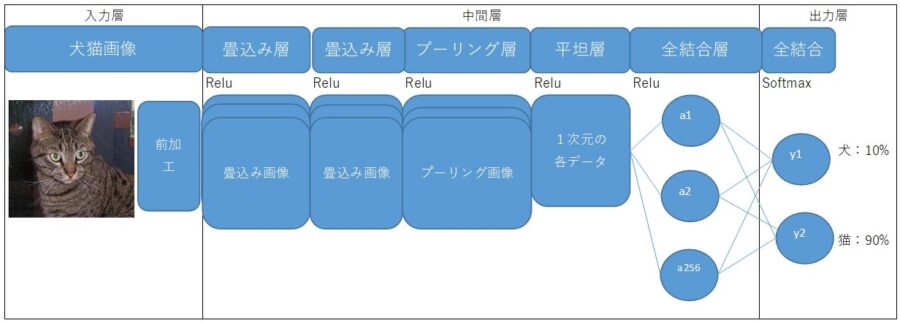
画像を読込み、犬猫データセットを設定
犬猫画像を読込み、犬猫データセットを設定します。
# -------------------------------------------------------------------
# 各種ライブラリのインポート
# -------------------------------------------------------------------
import os
import cv2
# -------------------------------------------------------------------
# 定数の定義
# -------------------------------------------------------------------
DATADIR = "./PetImages"
MODEL_DIR = "/content/drive/MyDrive"
CATEGORIES = ["Dog", "Cat"]
#IMG_SIZE = 150
IMG_SIZE = 50
# -------------------------------------------------------------------
# メイン処理(画像を読込み、犬猫データセットを設定)
# -------------------------------------------------------------------
#犬猫データセットを定義
training_data = []
#画像を読込み、犬猫データセットを設定
#(0:Dog、1:Cat)…class_numはCATEGORIESの配列index/categoryはCATEGORIESの中身
for class_num, category in enumerate(CATEGORIES):
#ディレクトリを設定(ループ1回目:./PetImages/Dog 2回目:./PetImages/Cat)
path = os.path.join(DATADIR, category)
for image_name in os.listdir(path):
try:
img_array = cv2.imread(os.path.join(path, image_name),) # 画像読み込み
img_resize_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE)) # 画像のリサイズ(50✕50)
training_data.append([img_resize_array, class_num]) # 画像データ(犬 or 猫)、ラベル情報(0 or 1)を追加
except Exception as e:
#画像の読込みエラーはスルー(スキップして次の画像へ)
pass犬猫データセット(training_data)のイメージはこんな感じ。
training_data配列で、0:Dogと1:Catを表現します。
画像の前加工+モデル作成・訓練・テスト
画像を正則化で前加工してからモデル作成・訓練・テストします。
処理の内容はコメントを見てくださいね♪
import numpy as np
import random
from sklearn import model_selection
from tensorflow.keras.models import Sequential
from tensorflow.keras import layers
from tensorflow.keras.callbacks import EarlyStopping
import matplotlib.pyplot as plt
TRAIN_SIZE = 5000
TEST_SIZE = 500
BATCH_SIZE = 32
EPOCHS = 20
# -------------------------------------------------------------------
# 関数の定義
# -------------------------------------------------------------------
# 正規化を行う関数:Xを0~1に変換する
# 引数(X)
# 戻り値(0~1)
def normalize(x):
x_max = np.max(x)
x_min = np.min(x)
return (x - x_min) / (x_max - x_min)
# -------------------------------------------------------------------
# メイン処理(画像の前加工+モデル作成・訓練・テスト)
# -------------------------------------------------------------------
##########################
# 画像の前加工
##########################
random.shuffle(training_data) # 犬猫データセットをシャッフル
X_train = [] # 画像データ
Y_train = [] # ラベル情報
# データセット作成
for feature, label in training_data:
X_train.append(feature)
Y_train.append(label)
# データセットをlist配列からNumpy配列に変換
X_train = np.array(X_train)
Y_train = np.array(Y_train)
# データセットの確認(サンプルで4つだけ)
for i in range(0, 4):
print("学習データのラベル:", Y_train[i])
plt.subplot(2, 2, i+1)
plt.axis('off')
plt.title(label = 'Dog' if Y_train[i] == 0 else 'Cat')
plt.imshow(X_train[i], cmap='gray')
plt.show()
#データセットを訓練データ(5000)とテストデータ(500)に分割
t = model_selection.train_test_split(X_train, Y_train, train_size=TRAIN_SIZE, test_size=TEST_SIZE)
train_feature, test_feature, train_label, test_label = t
#訓練データとテストデータを正規化(0~1の値に揃える)
train_feature = normalize(train_feature)
test_feature = normalize(test_feature)
##########################
# モデル作成・訓練・テスト
##########################
#モデルの定義 ⇒精度が上がるように自分で色々と工夫してみて♪
model = Sequential()
#入力-畳込み層-全結合層-出力(2:softmax)
#畳込み層 フィルタ(3✕3)を32枚 0パティングで入力と出力サイズが同じ 入力の形(50✕50✕3 最後の3はRGBの3)
model.add(layers.Conv2D(32,(3, 3), padding='same', activation='relu', input_shape=(IMG_SIZE, IMG_SIZE,3)))
#畳込み層 フィルタ(3✕3)を32枚
model.add(layers.Conv2D(32,(3, 3), activation='relu'))
#プーリング層 Max(2✕2)
model.add(layers.MaxPool2D(pool_size=(2,2)))
#平坦化層 1次元にする(2次元以上の入力データを1次元のデータに変換)
model.add(layers.Flatten())
#全結合層 256ユニット
model.add(layers.Dense(256, activation='relu'))
#全結合層 2ユニット(犬・猫)のsoftmax(それぞれの確率)
model.add(layers.Dense(2, activation='softmax'))
#最適化アルゴリズム、損失関数、評価関数のリスト設定
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
# EarlyStoppingの設定(テストの損失値が3回連続上昇するとエポックをストップ)
early_stopping = EarlyStopping(
monitor='val_loss',
mode='auto',
patience=3
)
#モデルを学習させる(メインは訓練データ グラフ可視化のためにテストデータを指定)
history = model.fit(train_feature, train_label, batch_size=BATCH_SIZE, epochs=EPOCHS, validation_data=(test_feature, test_label)
,callbacks=[early_stopping] # CallBacksにEarlyStoppingを設定
)
# 学習履歴の可視化・グラフ表示(accuracy)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.grid()
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()
# 学習履歴の可視化・グラフ表示(loss)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('loss')
plt.xlabel('Epoch')
plt.grid()
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()
#モデルの損失値と評価値を返す(テストデータ)
score = model.evaluate(test_feature, test_label, verbose=2)
#テストデータの損失値と評価値をプリント
print('Test loss:', score[0])
print('Test accuracy:', score[1])以下、実行結果です。
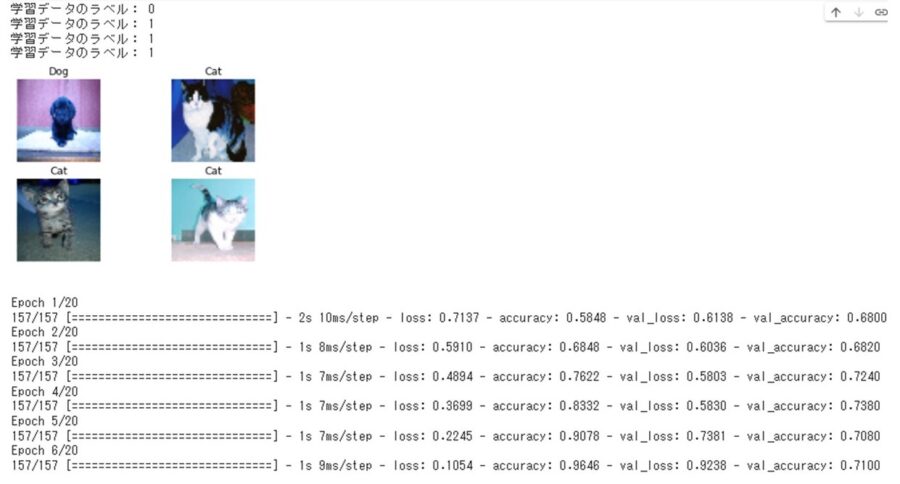
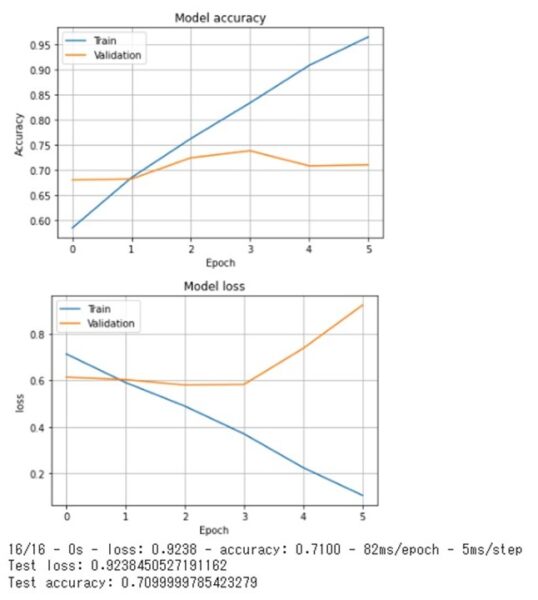
70%以上の精度がでていますね。
うーん。あと一歩というところでしょうか。
モデル等を調整して精度の改善にチャレンジしてみてください♪
目指せ99%!
「記事を読んでもわからないトコがある」「内容が変だよ」
という時は、お気軽にコメントください♪
「もっとSEおっさんに詳しく聞きたい。何かお願いしたい!」
という時は、ココナラまで。メッセージもお気軽に♪
LINEでのお問合わせも受付中!
LINE公式アカウント
メッセージをお待ちしています!
- 応用情報技術者
- Oracle Master Gold
- Java SE Gold
- Java EE Webコンポーネントディベロッパ
- Python エンジニア認定データ分析
- 簿記2級





