
GoogleColabでYOLOを使用した物体検出AIを実装方法をご紹介します。
今回は実装といっても、YOLOの学習モデルを使用しただけです。
超簡単でサクッとできちゃうぞ♪
物体検出の第1歩としてyoroを体感してみましょう。
でも…

『具体的にどうすんの?』
『そもそも物体検出って何?』
『画像や動画の準備はどうすんの?』
こんな疑問に答えます。

物体検出と物体認識の違い!アノテーションって何だ?

物体検出と物体認識の違いとアノテーションについてザックリで説明します。
物体検出と物体認識の違い
物体検出と物体認識は似てますが微妙に違うものです。
ザックリと違いを理解しよう♪
- 物体検出…画像内の位置を特定する
- 物体認識…画像内の物体を識別する
アノテーションとは
アノテーションとは、検出した物体を矩形領域で囲んで名称を表示させることです。
- アノテーション
検出した物体を矩形領域で囲んで名称を表示させること。
こんな感じのヤツがアノテーション。
お店に入る前のマスクチェックでアノテーションをよく見かけますね。

GoogleColabでYOLOの物体検出AIを実装する準備

GoogleColabでYOLOを使用した物体判定AIを作るには事前準備が必要です。
事前準備はとっても簡単だよ。Let’s Try!
GoogleColabを新規作成
GoogleColabでノートブックを新規作成しよう。
保存するとGoogleドライブに保存されます。
そのまま保存するとファイル名は「Untitled1.ipynb」になっちゃう。
「物体検出.ipynb」に変更してから保存してね♪
名前を変更せずに保存すると…
後から見た時「Untitled1.ipynb」では「なんのソースかわからんゾ」ってなる。

保存する名前は「何をしているのかわかる名前をつける」という癖をつけようー。
名前の変更はいつでもできるので安心してね♪
GoogleColabのランタイムをGPUへ変更
ソースを書く前にGoogleColabのランタイムをGPUへ変更します。
これをすると実行が早くなるよ。
GPUへ変更方法は下記をご覧ください♪

GoogleColabでGoogleドライブをマウント
GoogleColabを開いて、Googleドライブをマウントしよう。
マウント方法は下記をご覧ください♪

GoogoleドライブへアップロードしたZIPファイルがディレクトリ「drive/MyDrive」に表示されたら成功です!
ColabからGoogoleドライブへマウントできてるよ。
Googleドライブへディレクトリを移動

次のコマンドで、カレントディレクトリをGoogleドライブへディレクトリを移動します。
cd /content/drive/MyDriveちなみに、
カレントディレクトリを確認するOSコマンドはこちら。
!pwd/content/drive/MyDrive
OSコマンドの前にビックリマーク「!」を書くよ。
PythonコマンドとOSコマンドを混同しないためです。
なぜかcdコマンドはビックリマークはいりません(なんでかわかる人はコメントくださいー)
GoogleColabのOSはLinuxなので、
OSコマンド=Linuxのコマンド
です♪
GitHubからYOLO7をクローン&ディレクトリ移動

次のコマンドで、公式のGitHubからYOLOをクローンします。
今回はYOLOのバージョン7をクローンするよ。
!git clone https://github.com/WongKinYiu/yolov7クローンとは、コピーを作ると同じ意味です。
クローン細胞とか良く聞きますよね。
かなりザックリの説明ですが、なんとなくわかったかな。
成功するとGoogleドライブにyolov7というディレクトリが作成されます。
カレントディレクトリをyolov7へ移動させよう。
cd yolov7さっきから、カレントディレクトリをcdでちょこちょこ移動している理由は…
OSコマンドは基本的にカレントディレクトリが対象になるからです。
ディレクトリを指定するとカレント以外のディレクトリを対象にすることができますが、毎回指定するのはメンドクサイ。
カレントディレクトリを移動させた方が楽ちんです。

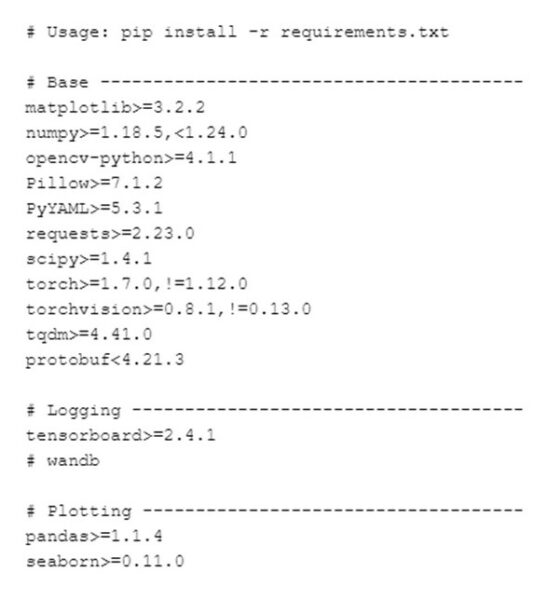
requirements.txtから必要なライブラリをインストール
requirements.txtとは、使用するライブラリのバージョンが記述されたファイルです。
これを使用すると必要なライブラリが一括でインストールされるよ。超便利やね。
次のコマンドで、必要なライブラリを一括でインストールします。
!pip install -r requirements.txtこんな感じで一括ダウンロードされるよ。
YOLOv7は学習済みモデルをダウンロード
YOLOv7は学習済みモデルがいくつも用意されています。
今回は推論結果が№1だった「yolov7-e6e.pt」を使用するよ。
モデルの比較は公式のgithubの掲載されてますので、興味のある方はご覧ください。

次のコマンドで、yolov7-e6e.ptをダウンロードします。
!wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7-e6e.ptwgetはネットからダウンロードするコマンドです。
便利だね♪
クローン(git clone)とダウンロード(wget)の違い

ダウンロード(wget)は、インターネットから指定したファイルをダウンロードします。
クローン(git clone)は、指定したGithubの資産をゴッソリとコピーします。
Githubのソース構成を丸ごとダウンロードしているイメージです。
クローンもダウンロードとやってることは基本的には同じように見えますが、単一か複数かの違いがあります。
「yolov7-e6e.pt」は単一ファイルなので、wgetでダウンロードしてるんだ。
なんとなく、わかったかな?
GoogleColabでYOLOの物体検出AIを実装する

事前準備が整ったので、GoogleColabでYOLOの物体検出AIを実装してみましょう。
コマンドはたった1行ですが、YOLOの物体検出を体感できます。
やってみよう!
YOLOを使用したサンプル画像の物体検出
次のコマンドで、サンプル画像の物体検出を実行します。
!python detect.py --source inference/images/ --weights yolov7-e6e.pt --conf 0.25 --img-size 1280 --device 0サンプル画像の保存先はyoro7ディレクトリの「inference/images」です。
–sourceオプションでディレクトリ「inference/images」を指定してますね。
inference/imagesにサンプル画像が6枚あります。
この6枚の物体検出を実行しているわけです。
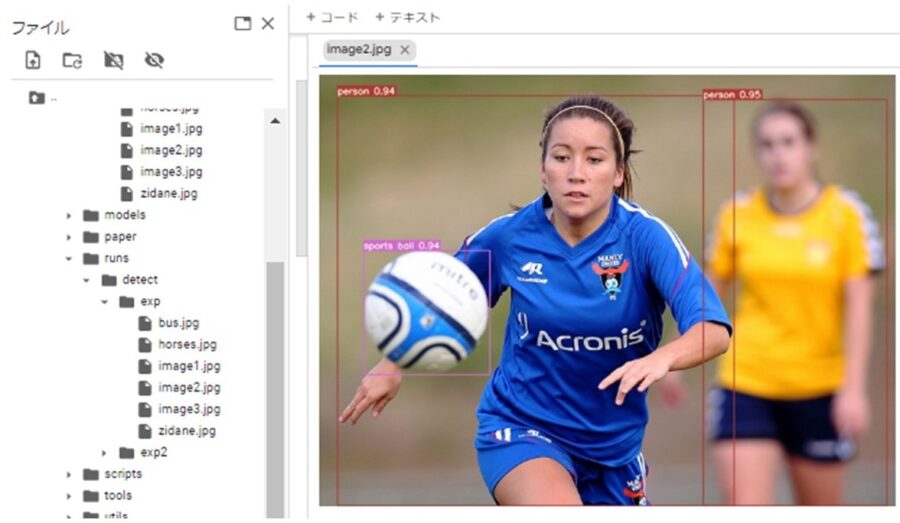
サンプル画像はこんな感じです。
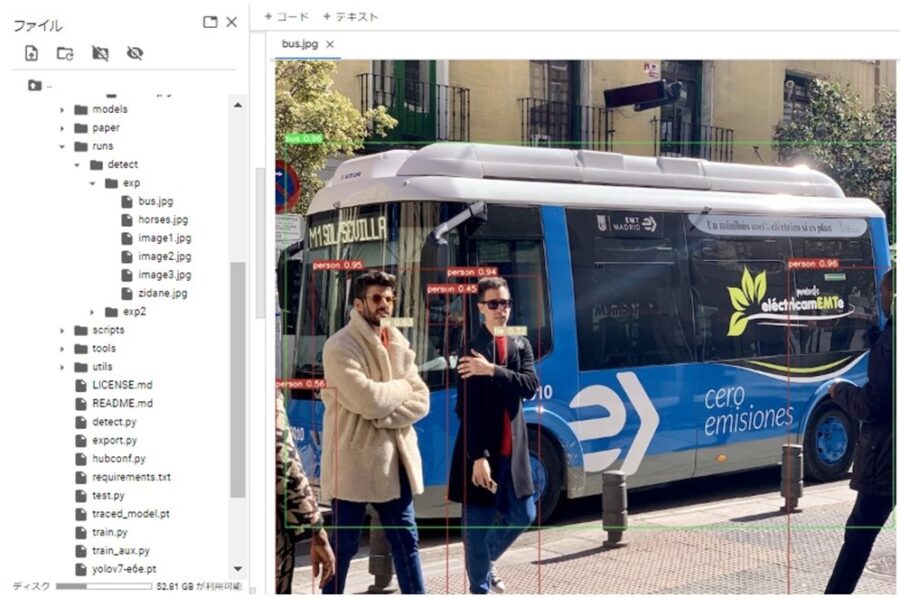
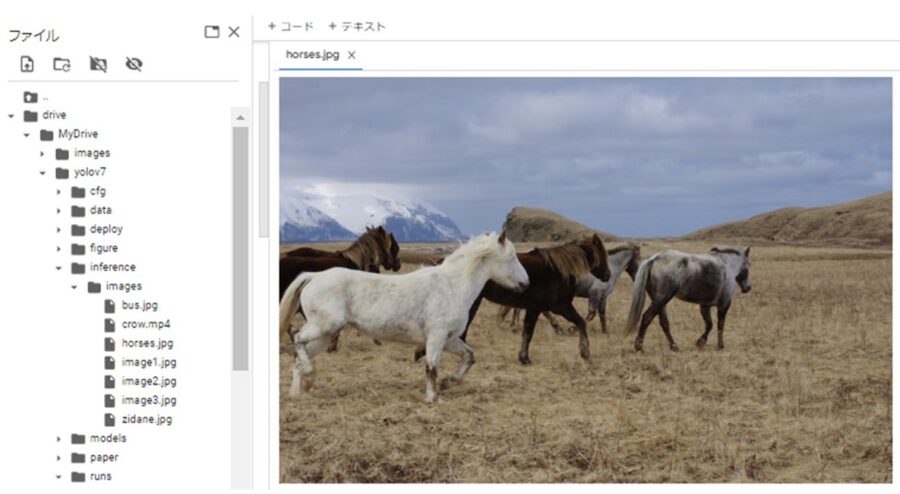
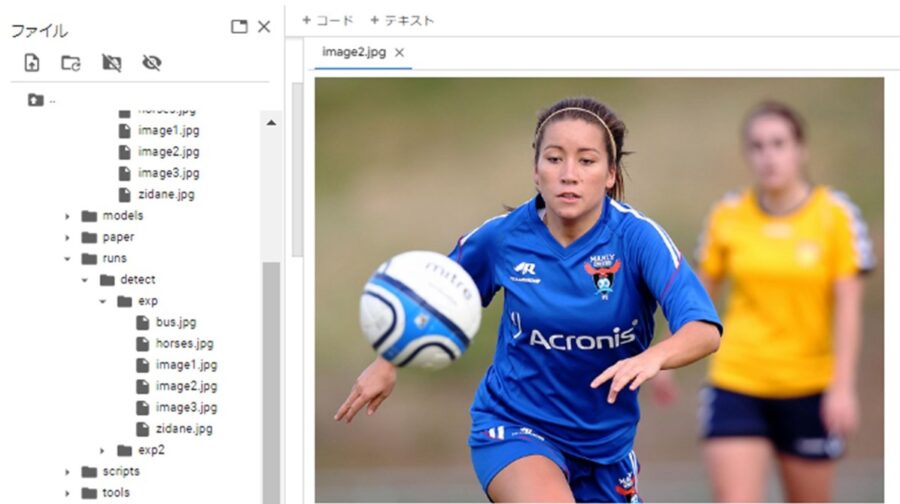
成功するとyolov7のディレクトリ「runs/detect/exp」にアノテーション付きの画像が作成されます。
ちゃんとラベリングされてますね。素晴らしい!

YOLOを使用した動画の物体検出
YOLOのモデルで動画の物体検出もできます。
今回はカラスの動画「crow.mp4」をyoro7ディレクトリの「inference/images」へアップロードしました。
こんな感じの動画です。

カラスの動画はpixabayなどのフリー素材サイトからダウンロードできるよ。
動画の対象となる拡張子は「.mov」か「.mp4」なので注意してね。
次のコマンドで、アップロードしたカラスの動画の物体検出を実行します。
!python detect.py --source inference/images/crow.mp4 --weights yolov7-e6e.pt --conf 0.25 --img-size 1280 --device 0成功するとyolov7のディレクトリ「runs/detect/exp2」にアノテーション付きの画像が作成されます。
実行するたびに、出力するディレクトリがexp2、exp3、exp4と増えていく仕様のようです。

ちゃんとbirdとラベリングされてますね。おぉ、Excellent!
でも、本当はbirdではなくcrow(カラス)と判定させたい。
次に応用を考えます(グダグダやで。先に言っとくわゴメン)
GoogleColabでYOLOの物体検出AIを応用する

GoogleColabでYOLOの物体検出を応用として考えてることを書きました。
まだ調査中なのでメモレベルです。ごめんm(_ _)m
「俺は知っているゾ」というアナタ。ぜひコメントをお寄せください♪
- birdではなくcrow(カラス)と認識させる
yorov7ディレクトリに「data/coco.yaml」というファイルで検出対象が定義されている模様。
ラベリングツールで自作のラベルを作れる模様。
ツールには「labelImg」「CVAT」「VoTT」がある
ラベリングさせる作業をアノテーションというときもある模様(違うかも)
アノテーションの結果としてcocoという形式がある模様(違うかも)
以前までは「labelImg」が使いやすかったようですが、「VoTT」も改善されて使いやすくなったみたい。
なので「VoTT」でカラスをアノテーションしようと思います。
「VoTT」をYOLO7に使用するには、アノテーション後でエクスポートしたjsonを「roboflow」というツールでYOLO形式に変換する必要があるようです。
アノテーションは大きな括りでいうと訓練データと教師データ(ラベル)ということかな。
訓練データとして、画像が必要ですね。
画像はこれで集めれるかな。
#カラスの画像をBingで100こ取得して保存 from icrawler.builtin import BingImageCrawler crawler = BingImageCrawler(storage={"root_dir": '保存先パス'}) crawler.crawl(keyword='カラス', max_num=100) - 物体検出の結果を取得する
detect.pyを実行オプションの付与
「–save-txt」を付与すると検出ラベルと座標が出力される
「–save-conf」を付与すると検出ラベルと座標の右横にスコアが出力される
出力されるディレクトリはyorov7ディレクトリの「runs/ditect/exp」
「–source」が動画の場合、「–save-txt」を付与して実行すると検出ラベルと座標が複数のファイルで出力された。 - リアルタイムにカメラで物体検出する
detect.pyを実行オプションの付与
「–source 0」 …webカメラ
「–source 1」 …usbカメラ
これでリアルタイムにカメラで物体検出できるっぽい
リアルタイムのカメラはcolabでは無理っぽい。やるならローカル環境でやるしかなさそう。 - リアルタイムにカメラでカラスの検出結果を取得して、ラズパイでブザーをならす
コチラで物体の検出数をカウントアップさせています。
これを参考にカラスに対してカウントアップできれば、ブザーまでもう一息だ(と信じてる)
初めはリアルタイムに出力された検出結果テキストファイルを読み取ってブザーをならせそうと考えていました。
しかし、現実的じゃないのでdetect.pyをカスタマイズに方針に変更しました。 - リアルタイムにカメラでカラスの検出結果を取得したら暴れるロボット(カカシ)をつくる
ブザーをならせたら、ロボットも動かせる(と信じてる)
「記事を読んでもわからないトコがある」「内容が変だよ」
という時は、お気軽にコメントください♪
「もっとSEおっさんに詳しく聞きたい。何かお願いしたい!」
という時は、ココナラまで。メッセージもお気軽に♪
LINEでのお問合わせも受付中!
LINE公式アカウント
メッセージをお待ちしています!
- 応用情報技術者
- Oracle Master Gold
- Java SE Gold
- Java EE Webコンポーネントディベロッパ
- Python エンジニア認定データ分析
- 簿記2級





